The 200X hot topic was Agile development in a FDA regulated setting. Over a decade later this should (hopefully) be a settled issue. I can’t imagine anyone still doing water-fall these days. The new challenge for medical device companies is implementing Full Cycle Teams (FCTs), which is well described in Full Cycle Developers at Netflix — Operate What You Build.
The 200X hot topic was Agile development in a FDA regulated setting. Over a decade later this should (hopefully) be a settled issue. I can’t imagine anyone still doing water-fall these days. The new challenge for medical device companies is implementing Full Cycle Teams (FCTs), which is well described in Full Cycle Developers at Netflix — Operate What You Build.
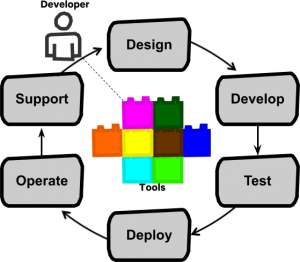
This organizational structure increases the speed of feature delivery and allows for experimentation to further improve the customer experience. Tooling and automation ("paved roads") are key. The model that Netflix came up with:
"Full cycle developers" is a model where a development team, equipped with amazing developer productivity tools, is responsible for the full software life cycle: design, development, test, deploy, operate, and support.
If you work for a large enough enterprise, you likely have teams of people that provide the following functions:
- Product development (creates and designs applications software and includes architects, product owners, and scrum masters)
- Quality assurance (QA). They test the software. For a medical device company, we call this team Verification and Validation (V&V)
- Site Reliability Engineering (SRE). Ensures scalability and reliability of the infrastructure and applications. They do performance testing and may implement some Chaos engineering techniques.
- Development operations (DevOps). Manage the code repositories, shared development tools, CI/CD pipelines, middleware, databases, etc.
- Infrastructure management (on-prem hardware and operating systems)
- Cloud management (same as above, but in the cloud)
- Applications support (monitor and manage applications in production)
Do not confuse FCTs with "Full Stack Teams" (see Full Stack Pronounced Dead). This "stack" refers to technologies that are used to implement a typical web-based application (e.g. LAMP).
FCTs are about supporting functionality end-to-end (product idea to production), but both have the challenge of developer specialization in common. A FCT has to broaden their skill-set even further to include application/infrastructure deployment, monitoring, and support. This is the future!
Full Cycle Team Challenges for Medical Device Companies
The transformation from a legacy organization (as described above) to FCTs is made even more challenging for a medical device company creating software that has to maintain FDA regulatory controls (see Quality System Regulation Subpart C–Design Control § 820.30).
Below is a list of regulatory and transition considerations that impact the release process. Most are associated with keeping the Design History File (DHF) documentation up-to-date. The organizational challenge in a FCT world is figuring out who is responsible for these tasks.
Spoiler alert: The suggested answers should be obvious, but many times the best I can do is just ask the question. Every organization, and even different teams within a single organization, will have different solutions. These can be tough problems to solve. Don't shoot the messenger!
Medical Device Data System (MDDS)
Not all of your software may be under FDA Class II/III regulatory controls. Some could fall under MDDS, see Identifying an MDDS. There is still some risk associated with MDDS but special controls and premarket approval -- the 510(k) -- are not necessary (see MDDS Rule).
MDDS software requires the same QMS documentation (see MDDS Section VI-E. Current Good Manufacturing Practices (CGMP)/QS Regulation/MDR Compliance of the rule) so most of the items listed here still apply.
Also, see Comment 25 from the rule which addresses "modular software". I.e mixing MDDS components with medical device components. The response says "The MDDS regulation does not necessarily prevent modular implementation.", but the FDA can't make a "generalized determination" on the various ways these combinations may be made. This may be a situation you run into and the FDA suggests it is best to contact them if you have questions.
Validation and Verification
General Principles of Software Validation; Final Guidance for Industry and FDA Staff (PDF)
Based on the intended use and the safety risk associated with the software to be developed, the software developer should determine the specific approach, the combination of techniques to be used, and the level of effort to be applied. While this guidance does not recommend any specific life cycle model or any specific technique or method, it does recommend that software validation and verification activities be conducted throughout the entire software life cycle.
FDA guidance documents, and FDA regulations in general (e.g. IEC 62304), tell you what to do, but leave the how up to the organization.
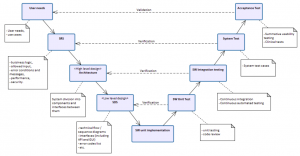
Let's highlight the SRS* to System test verification from the V-model. This is essentially end-to-end testing. In a microservice-based architecture, each FCT is likely responsible for different sets of services. These services may be dependent on the services provided by other teams.
Which team is responsible for ensuring that the entire system is functioning properly (i.e. end-to-end test protocols and results) after changes are made to one or more of these services?
In an ideal world, these end-to-end tests are completely automated, but even then someone still needs to maintain them.
Validation testing (was the right product built?) presents even more challenges as a single FCT is may only be responsible for a small portion of the entire product.
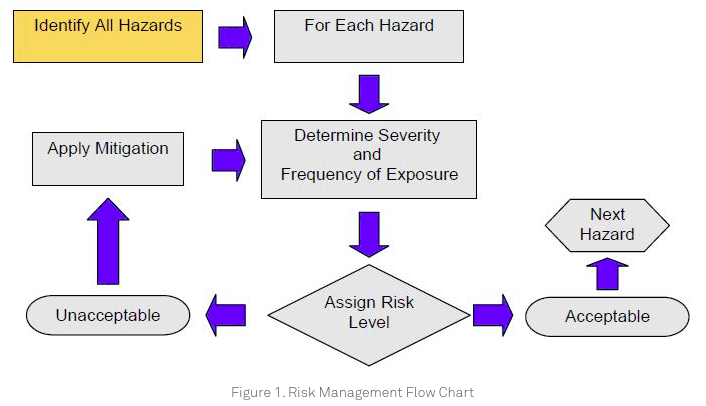
Risk analysis
From Medical Device Design Risk Management Basic Principles:
Risk analysis is typically done by a cross-functional team that may span multiple business units, but it is probably not unreasonable for the FCT Product Owner to drive this process and get the documentation updated as needed.
Traceability
From the FDA guidance:
A source code traceability analysis is an important tool to verify that all code is linked to established specifications and established test procedures.
Creating this documentation is well suited for automation. It still requires ensuring that all requirements and related test scenarios are properly tagged so they can be parsed to produce a release report.
Software Design Evidence
From the FDA guidance:
The Quality System regulation requires that at least one formal design review be conducted during the device design process. However, it is recommended that multiple design reviews be conducted (e.g., at the end of each software life cycle activity, in preparation for proceeding to the next activity).
This is a challenge for any Agile-based development process so is not specific to the FCT-based organization. Running formal design reviews as early in the development process as possible should be a team responsibility.
Manual Approval Gates
For many unregulated software products continuous integration (CI) and continuous delivery (CD) is a reality. I.e. Code can be pushed, run through the CI/CD pipelines, and delivered to customers without human intervention.
It is very unlikely (not impossible though I suppose, depending on the product) that this would occur for FDA-regulated software. Even with automated document generation, software deployment to production will still require human sign-off steps and audit trails.
Off-The-Shelf (OTS) Software
OTS/SOUP Software Validation documentation needs to be kept up-to-date. This is mostly a book-keeping exercise for OTS/SOUP that is part of the software product. For tools though, see OTS/SOUP Software Validation Strategies.
Another consideration to keep in mind for including 3rd party software into your product is the software license. The corporate (legal) policy should dictate license requirements, but teams would be aided by an automated tracking process.
Infrastructure
Installation, operational, and performance qualification -- IQ/OQ/PQ. FDA regulated software must have these processes in place to ensure that after any changes are made, the infrastructure continues to meet quality requirements. With the microservice architecture becoming a best practice, the team would now be responsible for documenting the IQ/OQ/PQ for their particular microservice or container flavor(s).
Cloud Offerings
Serverless architectures (Note: I'm most familiar with AWS, so will use their cloud products as examples. Azure and GCP have similar offerings.) One of the key advantages of the Lambda, Fargate, RDS, and similar managed/SaaS products is their undifferentiated heavy lifting. AWS is responsible for the care and maintenance of the underlying infrastructure and servers. For on-prem servers, this is something the organization spends significant time and money on, but these expenditures do not directly benefit the customer. Serverless allows companies to focus their efforts on things that make a difference to their customers.
How do you ensure IQ/OQ/PQ quality when you don't have control over the servers that are running your application(s)?
Another consideration: Teams will need to take regulatory impact into consideration when selecting new cloud technologies.
Infrastructure as Code (IaC)
The use of IaC (e.g. CloudFormation or Terraform) may require new release cycle processes. I.e since this code is not part of the application, you may want to have a separate release cycle for when the infrastructure is updated. The same is true for container (Docker) code updates.
The FCT should be responsible for the IaC associated with their product as it directly impacts both functionality and performance.
Transformation
When thinking about transforming to a FCT-based organization, the 2019 AWS re:invent keynote by Andy Jassy comes to mind. His "transformation" is referring to migrating from on-premise to cloud infrastructure (AWS, of course), but I think the non-technical transformation recommendations he outlines (start: 5:04 end 11:48) are also applicable to the FCT organizational change:
I think aggressive goals (item #2) is particularly important. Legacy organizations have a lot of inertia that needs to be overcome in order to move things forward. Breaking those initial barriers is even more difficult when you're having to deal with regulatory requirements.
Bottom Line
FDA regulatory requirements add tasks and documentation to the software release process. This has always been the case for medical device companies, but how this additional work is managed when trying to implement full-cycle teams can be a complicated problem to solve.
Just like unregulated development, providing the tooling to automate these tasks is the key to allow teams to deliver quality software to customers more quickly.
---------------
*SRS, Software Requirements Specification. The old-school water-fall requirements document. I don't miss those days!

 For me, the primary takeaway from Paul Graham's Putting Ideas into Words is this:
For me, the primary takeaway from Paul Graham's Putting Ideas into Words is this:
 The
The